上篇地址:6大部分,20 个机器学习算法全面汇总!!建议收藏!(上篇)-CSDN博客
上篇介绍了
接下来介绍新的内容
半监督学习算法
半监督学习算法结合了监督学习和无监督学习的元素,利用既有的标记数据和未标记数据来训练模型。
这样可以充分利用有限的标记数据,提高模型的性能和泛化能力,尤其适用于数据稀缺或昂贵标记的情况。
1、标签传播
将标签从已知样本传播到未知样本。
标签传播(Label Propagation)是一种半监督学习方法,通常用于图数据或网络数据中的节点分类问题。其基本原理是利用已知标记的数据节点(种子节点)来传播标签,从而对未标记的节点进行分类。标签传播算法试图使相邻节点的标签相似,从而实现对整个图数据的标签传播。
基本原理
1、种子节点:标签传播算法需要一些已知标记的数据节点,这些节点被称为种子节点或初始标签节点。通常,这些种子节点包含了一些数据的真实标签。
2、标签传播:算法开始时,种子节点的标签被用作初始标签。然后,通过迭代地更新未标记节点的标签,使其与相邻节点的标签相似。这个相似性通常基于数据节点之间的关系或相似性度量。
3、标签更新规则:标签传播算法通常使用以下规则来更新节点的标签:
-
对于每个未标记节点,计算其相邻节点的平均标签(或加权平均标签)作为新的标签。
-
重复上述步骤,直到标签不再发生显著变化或达到预定的迭代次数。
核心公式
标签传播算法的核心公式涉及到标签的更新规则。
通常使用以下公式来更新节点 i的标签 yi:
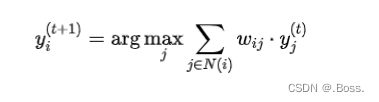
需要注意的是,标签传播算法的效果受到种子节点的选择、权重计算方法和收敛条件的影响。算法通常可以很好地处理图数据中的标签传播问题,但在某些情况下可能出现标签震荡或收敛到不稳定状态的问题,因此需要谨慎调整参数和监控算法的收敛情况。
2、自训练
自训练(Self-training)是一种半监督学习方法,其基本原理是通过已标记的数据和部分未标记的数据来进行模型训练和标签预测。自训练通常涉及以下步骤:
基本原理
1、已标记数据:首先,使用一小部分已标记的数据进行初始模型训练。这是传统的监督学习阶段,用于建立初始模型。
2、标签传播:接下来,使用已训练的模型来预测未标记数据的标签。这些预测的标签被添加到未标记数据上,以扩充已标记数据集。
3、再训练:使用扩充后的数据集(包括已标记数据和具有估计标签的未标记数据),重新训练模型。这个新模型通常能够更好地捕捉数据的分布和特征,因为它包含了更多的数据。
4、迭代:迭代执行标签传播和重新训练的步骤,直到满足停止条件(例如,达到最大迭代次数或标签预测不再发生明显变化)。
核心公式
自训练的核心公式涉及到标签预测和重新训练的过程。以下是一些关键的公式:
1、标签预测:使用已训练的模型来预测未标记数据的标签。通常,这涉及到计算每个类别的分数(例如,使用 softmax 函数),然后选择分数最高的类别作为预测的标签。对于分类问题,标签预测公式可以表示为: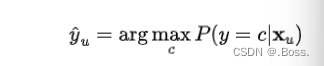
2、重新训练:使用扩充后的数据集重新训练模型。通常,这包括使用已标记数据和具有估计标签的未标记数据来计算损失函数,并通过反向传播算法来更新模型参数。重新训练可以使用传统的监督学习算法进行。
自训练是一种利用未标记数据提高模型性能的有用方法,特别是在数据稀缺的情况下。然而,自训练也存在一些挑战,例如标签传播的误差可能会被积累,导致模型性能下降。因此,在应用自训练时需要仔细考虑数据的质量和迭代策略,以获得最佳性能。
强化学习算法
强化学习算法的目标是通过与环境的互动来学习如何采取行动以最大化累积奖励。
在强化学习中,Agent 通过观察环境的状态、选择行动并接收奖励来学习。它不需要显式的标签,而是通过尝试不同的行动来优化策略,以最大程度地提高长期累积奖励。强化学习广泛应用于自动控制、游戏、机器人、自动驾驶等领域,其中代理通过与环境的互动来学会逐渐提高性能。
1、Q-Learning
Q-Learning 是强化学习中的一种基本算法,用于解决马尔可夫决策过程(Markov Decision Process,MDP)中的单智能体问题。Q-Learning 的主要目标是学习一个值函数(Q值函数),该函数表示在每个状态下采取每个动作的预期回报。通过学习这个值函数,智能体可以在环境中选择最优的动作来最大化累积奖励。
基本原理
1、状态(State)和动作(Action):Q-Learning 基于马尔可夫决策过程,其中有一组状态和一组可用的动作。智能体根据当前状态选择动作,然后观察奖励和下一个状态,依此不断进行决策。
2、Q值函数:Q-Learning 的核心是学习一个Q值函数(也称为动作值函数),通常用 表示。这个函数表示在状态 下采取动作 的预期回报。
3、Bellman方程:Q值函数满足Bellman方程,该方程表示Q值函数与下一个状态的Q值之间的关系。Bellman方程通常如下所示:
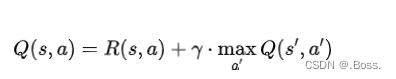
4、策略(Policy):智能体根据Q值函数来选择动作的策略。通常,可以使用ε-greedy策略,以一定的概率选择具有最大Q值的动作,以便探索环境。
核心公式
Q-Learning 的核心公式是Q值函数的更新规则,通常使用以下公式来更新Q值函数:
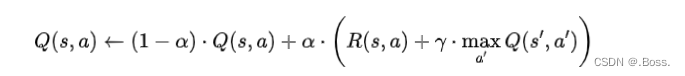
Q-Learning 是一个强大的强化学习算法,可用于解决许多单智能体问题,包括机器人控制、游戏玩法优化和自动决策制定等应用。它是强化学习领域的重要基础,并已被扩展和改进以适应更复杂的问题和多智能体场景。
2、深度强化学习
深度强化学习(Deep Reinforcement Learning,DRL)是一种结合深度学习和强化学习的方法,用于解决复杂的决策问题。DRL的基本原理是通过深度神经网络(Deep Neural Networks)来估计和优化代理(Agent)在环境(Environment)中采取动作以最大化累积奖励的策略。以下是DRL的基本原理和一些核心公式:
基本原理
1、代理和环境:DRL中的问题通常被建模为一个代理与环境交互的过程。代理在环境中观察状态,采取动作,并获得奖励。
2、状态(State):状态是代理观察到的环境信息,它可以是部分可见的或完全可见的,取决于具体问题。
3、动作(Action):动作是代理在状态下可以选择的操作,它可以是离散的(例如,移动棋子的位置)或连续的(例如,控制机器人的速度)。
4、奖励(Reward):奖励是代理在执行动作后从环境中获得的数值反馈,表示动作的好坏。代理的目标是最大化累积奖励。
5、策略(Policy):策略定义了代理如何根据观察到的状态选择动作。它可以是确定性策略或随机策略。
6、值函数(Value Function):值函数估计了在当前状态或状态-动作对下获得累积奖励的预期值。值函数包括状态值函数(V值函数)和动作值函数(Q值函数)。
核心公式
1、马尔可夫决策过程(MDP):DRL通常基于马尔可夫决策过程来建模问题。MDP包括状态空间 、动作空间 、状态转移概率 、奖励函数 和折扣因子 。
2、Q-Learning更新规则:DRL中常用的Q-Learning更新规则是基于Bellman方程的更新。对于Q-Learning算法,Q值更新规则如下:
其中, 是状态-动作对 的 值, 是在状态 下采取动作 后获得的奖励, 是从状态 采取动作 后的下一个状态, 是在状态 下可能的动作, 是学习率, 是折扣因子。
3、策略梯度方法:DRL还使用策略梯度方法来优化策略网络,其中目标是最大化期望累积奖励。这涉及到计算策略梯度并使用梯度上升方法来更新策略网络参数。
4、深度神经网络:DRL中通常使用深度神经网络来估计Q值、策略或值函数。深度神经网络可以是卷积神经网络(CNN)或循环神经网络(RNN),根据问题的性质而定。
DRL方法如深度Q网络(DQN)、深度确定性策略梯度(DDPG)、A3C(Asynchronous Advantage Actor-Critic)等已经在许多领域取得了显著的成功,包括游戏、机器人控制、自动驾驶和自然语言处理等。它们通过组合深度学习和强化学习,使得代理能够在复杂的环境中自主学习并优化策略。
集成学习算法
集成学习算法通过将多个基本模型组合在一起来提高预测性能和泛化能力。
集成学习的核心思想是“众口难调”:通过组合多个模型的预测,可以降低单个模型的错误率,并在复杂的问题上取得更好的性能。常见的集成学习方法包括随机森林、梯度提升、AdaBoost等,它们通过不同的方式组合基本模型,如决策树或分类器,以改善整体预测效果。集成学习在各种机器学习任务中都表现出色,包括分类、回归和特征选择等。
1、随机森林
随机森林(Random Forest)是一种集成学习算法,主要用于分类和回归问题。它基于决策树构建,并通过随机性引入多个决策树的组合来提高模型的性能和鲁棒性。以下是随机森林的基本原理和核心概念,不涉及具体的数学公式。
基本原理
1、决策树集成:随机森林是一个由多个决策树组成的集成模型。每个决策树都是基学习器,用于解决分类或回归问题。
2、随机性:随机森林引入了随机性来创建多样性的决策树。这包括两种主要随机性因素:
-
随机采样:从训练数据集中随机选择一个子样本,通常采用自助采样(Bootstrap Sampling)方法,这使得每个决策树的训练数据不同。
-
随机特征选择:在每个节点上,只考虑特征的随机子集进行分割。这确保了每个决策树的节点划分不同,增加了多样性。
3、投票或平均:在分类问题中,随机森林通过多数投票来选择最终的类别。在回归问题中,它通过取多个决策树的平均预测值来得到最终的预测。
4、Bagging:随机森林的每个决策树都是通过自助采样(Bootstrap Sampling)方式从训练数据集中生成的。这意味着某些样本可能会多次出现在一个决策树的训练集中,而其他样本可能根本不出现。这种方法称为“装袋”(Bagging),有助于减小方差,提高模型的泛化性能。
5、特征重要性:随机森林可以估计每个特征的重要性,通过观察在决策树的分裂中每个特征被使用的频率以及它们对模型性能的影响来进行评估。
核心步骤
随机森林的核心思想是集成多个决策树的结果,通过投票或平均来得到最终的预测结果。可以概括为以下过程:
1、对于每个决策树:
-
随机选择一个自助采样的训练数据集。
-
在每个节点上,随机选择一个特征子集进行节点分裂。
-
通过构建树结构来拟合模型,直到达到停止条件(例如,树的深度达到预定值或节点上的样本数小于阈值)。
2、对于分类问题,最终的预测结果是多个决策树的多数投票。对于回归问题,最终的预测结果是多个决策树的平均预测值。
总之,随机森林通过利用多个随机化的决策树来减小过拟合风险,并具有良好的泛化性能,使其成为一个强大的集成学习算法。
2、梯度提升
梯度提升(Gradient Boosting)是一种集成学习方法,用于解决回归和分类问题。它通过逐步迭代训练多个弱学习器(通常是决策树),每次迭代都校正前一轮的错误,从而提高模型的性能。
基本原理
1、弱学习器的组合:梯度提升是一个集成学习算法,它通过组合多个弱学习器(通常是决策树)来构建一个强大的集成模型。每个弱学习器在单独的情况下可能性能较差,但通过组合它们,可以获得更强大的模型。
2、迭代训练:梯度提升通过迭代的方式训练弱学习器。每次迭代都试图校正前一轮迭代的模型错误。这是通过拟合一个新的弱学习器来实现的,该学习器关注前一轮的残差或梯度,以便更好地拟合数据。
3、残差拟合:在回归问题中,每次迭代的目标是拟合前一轮模型的残差(即实际值与预测值之间的差异)。在分类问题中,目标是拟合前一轮模型的负梯度。
4、加权组合:弱学习器的预测结果按照一定权重进行组合,以获得最终的模型预测。通常,更准确的弱学习器会获得更高的权重。
5、正则化:梯度提升通常包括正则化项,以防止过拟合。正则化可以通过限制每次迭代中弱学习器的复杂性来实现。
核心思想
1、初始化一个初始模型,通常是一个常数(对于回归问题)或一个均匀分布的初始类别概率(对于分类问题)。
2、对于每次迭代(通常包括多个迭代):
-
计算前一轮模型的残差(对于回归问题)或梯度(对于分类问题)。
-
拟合一个新的弱学习器以减小残差或梯度。
-
计算弱学习器的权重,通常根据拟合质量来确定。
-
更新模型的预测,将新的弱学习器的预测与前一轮的预测组合。
3、最终的模型是所有弱学习器的组合,它的预测结果是所有弱学习器预测结果的加权组合。
梯度提升的一种常见变体是梯度提升树(Gradient Boosting Trees),其中每个弱学习器是决策树。著名的梯度提升算法包括梯度提升机(Gradient Boosting Machine,GBM)、XGBoost、LightGBM和CatBoost等。这些算法在实际问题中广泛应用,因为它们在性能和鲁棒性上表现出色。
3、AdaBoost
AdaBoost(Adaptive Boosting)是一种集成学习算法,主要用于二分类问题。它通过逐步训练多个弱学习器(通常是决策树或其他简单模型),并为每个弱学习器分配权重,以提高模型的性能。以下是AdaBoost的基本原理和一些核心概念,不涉及具体的数学公式。
基本原理
1、弱学习器的组合:AdaBoost的核心思想是组合多个弱学习器以构建一个强大的分类器。弱学习器是那些在单独情况下性能略高于随机猜测的模型。虽然弱学习器可能很弱,但通过它们的组合,可以得到一个强学习器。
2、样本权重:AdaBoost为每个训练样本分配一个权重,初始时,所有样本的权重相等。在每一轮的训练中,AdaBoost关注之前轮中被错误分类的样本,并为这些样本增加权重,以便在下一轮中更好地拟合它们。
3、弱学习器的权重:每个弱学习器也被分配一个权重,该权重表示其在最终分类器中的重要性。弱学习器的权重与其在每一轮训练中的性能相关,性能越好的学习器获得的权重越大。
4、加权投票:最终的分类器是所有弱学习器的加权组合,其中每个学习器的权重由其性能决定。分类时,每个学习器根据其权重投票,最终的预测结果由多数投票决定。
核心思想
AdaBoost 的核心公式涉及样本权重的更新和弱学习器的权重计算。
1、初始化样本权重:初始时,所有训练样本的权重相等。
2、对于每一轮的迭代:
-
训练一个弱学习器,尽力减小前一轮中被错误分类的样本的权重。
-
计算弱学习器的权重,通常与其性能有关。
-
更新样本权重,增加被错误分类的样本的权重。
3、最终的分类器是所有弱学习器的加权组合,其中每个学习器的权重由其性能决定。
AdaBoost的关键思想是将多个弱学习器组合成一个强大的分类器,通过关注错误分类的样本和调整权重来逐步提高性能。它在实际问题中表现出色,尤其在处理复杂数据集时,它可以提供出色的性能。
深度学习算法
深度学习算法模仿人脑神经网络的结构和功能,通过多层神经网络来学习复杂的特征表示和模式。
深度学习的核心是深度神经网络,其中包括多个神经网络层(通常称为隐藏层),每一层都包含多个神经元。这些网络层之间的连接具有权重,通过大量的训练数据,这些权重被调整以最小化模型的预测误差。
1、卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)是一种深度学习模型,主要用于图像处理和计算机视觉任务。CNN的基本原理是通过卷积层、池化层和全连接层来提取图像特征并进行分类。以下是CNN的基本原理和核心概念,以及一些核心公式。
基本原理
1、卷积操作:CNN使用卷积操作来捕获图像中的局部特征。卷积操作是通过将一个小的滤波器或卷积核与图像的不同位置进行卷积运算来实现的。这允许网络学习图像中的边缘、纹理和其他低级特征。
2、池化操作:在卷积层之后,CNN通常使用池化层来减小特征图的尺寸,同时保留最重要的特征。池化操作通常是最大池化(Max Pooling)或平均池化(Average Pooling)。
3、多层堆叠:CNN通常由多个卷积层和池化层堆叠而成,每一层都可以学习不同级别的特征,从低级特征(如边缘)到高级特征(如物体部分或整个物体)。
4、全连接层:在CNN的顶部,通常有一个或多个全连接层,用于将卷积和池化层的特征映射到最终的分类或回归输出。全连接层可以学习特征之间的复杂关系。
5、激活函数:每个卷积层和全连接层通常会应用一个激活函数,如ReLU(Rectified Linear Unit),以引入非线性性质。这有助于网络模型捕获非线性特征。
核心公式
虽然CNN的基本原理涉及卷积、池化和全连接操作,但它们可以用一些核心公式表示:
1、卷积操作:卷积操作可以用以下公式表示:
CNN的训练过程通常涉及反向传播算法,该算法用于计算损失函数的梯度并更新网络参数。尽管反向传播的详细数学公式相对复杂,但它是CNN训练的关键部分,通过梯度下降法来优化网络权重和偏置,以减小损失函数。CNN已经在图像分类、对象检测、语义分割和许多其他计算机视觉任务中取得了显著的成功。
2、循环神经网络
循环神经网络(Recurrent Neural Networks,RNN)是一类深度学习模型,主要用于处理序列数据,如时间序列、文本、音频等。RNN具有一种递归的结构,允许信息从当前时间步传递到下一个时间步,以捕捉序列中的时间依赖关系。以下是RNN的基本原理和一些核心概念,以及一些核心公式。
基本原理
1、递归结构:RNN具有递归结构,它在每个时间步接受输入并生成输出,同时维护一个隐藏状态(Hidden State),用于捕捉序列数据中的信息。隐藏状态在每个时间步根据当前输入和前一个时间步的隐藏状态进行更新。
2、时间依赖性:RNN的核心思想是捕捉序列数据中的时间依赖性。每个时间步的隐藏状态包含了来自前面时间步的信息,因此可以用来预测下一个时间步的输出。
3、参数共享:在RNN中,相同的权重和偏置被用于每个时间步的输入和隐藏状态的计算。这种参数共享使得RNN具有处理不定长序列的能力。
4、梯度消失和梯度爆炸:传统RNN存在梯度消失和梯度爆炸的问题,导致在训练深层RNN时难以捕捉长期时间依赖性。为了解决这个问题,许多改进型RNN模型已经被提出,包括长短时记忆网络(LSTM)和门控循环单元(GRU)等。
核心公式
虽然RNN的具体结构和变种有多种,以下是传统RNN的核心计算公式:
1、隐藏状态更新:RNN中的隐藏状态更新通常使用以下公式:
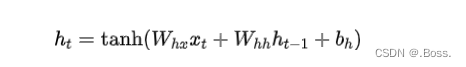
1、隐藏状态更新:RNN中的隐藏状态更新通常使用以下公式:
其中, 是时间步 的隐藏状态, 是时间步 的输入, 和 是权重矩阵, 是偏置。 是双曲正切函数,用于引入非线性。
2、输出计算:RNN的输出通常使用以下公式:
其中, 是时间步 的输出, 是权重矩阵, 是偏置。
3、时间步的循环:RNN通过将当前时间步的隐藏状态 传递给下一个时间步,从而实现信息的传递和时间依赖性的捕捉。
请注意,传统RNN存在梯度消失和梯度爆炸问题,因此在实际应用中,常常使用改进型RNN模型,如LSTM和GRU,来更好地处理长序列和时间依赖性。这些改进型模型引入了门控机制,以更好地控制梯度流动和捕捉长期依赖性。
3、Transformer
Transformer是一种深度学习模型,广泛应用于自然语言处理(NLP)任务,如机器翻译、文本生成和文本分类等。它在处理序列数据时采用了一种全新的架构,摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),取得了显著的成功。
基本原理
1、自注意力机制(Self-Attention):Transformer的核心是自注意力机制,它允许模型在输入序列中的任何位置都能关注到其他位置的信息,而不受限于固定的窗口大小。这种注意力机制有助于捕捉长距离依赖关系。
2、多头注意力(Multi-Head Attention):Transformer将自注意力机制扩展为多个注意力头,每个头学习不同的注意力权重,以便同时关注不同特征子空间中的信息。多头注意力可以提高模型的表达能力。
3、位置编码(Positional Encoding):由于自注意力机制不包含序列的顺序信息,Transformer引入了位置编码来将每个输入位置的绝对位置信息嵌入到输入嵌入向量中。
4、编码器-解码器结构:Transformer通常由编码器和解码器组成。编码器用于处理输入序列,解码器用于生成输出序列。编码器和解码器都包含多层自注意力和全连接层。
5、残差连接和层归一化:每个子层(自注意力或全连接层)之后都采用了残差连接和层归一化,以稳定训练并促进信息流动。
核心公式
Transformer涉及许多数学细节,但以下是Transformer中的一些核心公式:
1、自注意力机制(Scaled Dot-Product Attention):自注意力机制的计算可以概括为以下几个步骤,其中 表示查询向量, 表示键向量, 表示值向量:
-
计算注意力分数:
-
计算加权和: 其中, 是查询和键的维度, 函数用于将注意力分数转化为权重。
2、多头自注意力(Multi-Head Self-Attention):多头自注意力的计算如下,其中 表示头的数量,、、 分别表示第 个头的权重矩阵:
-
对每个头 ,计算 、、,然后应用自注意力机制。
-
将所有头的结果拼接并乘以权重矩阵 。
3、位置编码(Positional Encoding):位置编码的计算通常采用正弦和余弦函数的组合,以将绝对位置信息嵌入到输入嵌入向量中。
4、编码器-解码器注意力(Encoder-Decoder Attention):在解码器中,编码器-解码器注意力用于将解码器的自注意力与编码器的输出进行关联,以便在生成输出序列时引入输入序列的信息。计算方法类似于自注意力,但查询来自解码器,而键和值来自编码器的输出。
Transformer模型的成功在NLP领域产生了革命性的影响,并已经应用于各种自然语言处理任务,如机器翻译、文本生成、文本分类、问答系统等。其灵活性和能力使其成为当今深度学习中的一个重要模型架构。
最后
好了,朋友们,上面咱们列举的 20 个机器学习的核心原理和思路,算是有效的帮助大家做了一个总结!每种算法都有其自身的优点和适用领域,选择算法取决于任务的性质和数据的特点。
喜欢的朋友可以收藏、点赞、转发起来!
谢谢观看。

![[C++核心编程-08]----C++类和对象之运算符重载](https://img-blog.csdnimg.cn/direct/730eea47b2ad4e208f5b00f0a28ce6cb.png)